Behind the Code: Sports-Reference Founder Sean Forman
Behind the Code is an interview series centered around the sports-related web sites we use every day. The first installment features Sports-Reference founder Sean Forman.
For the first century of sports, newspapers, almanacs, and baseball cards were the medium of choice for communicating statistics. But the world of sports statistics has gone from paper to electric in less than two decades — and the Sports-Reference family of websites has been a key component in that transition.
We caught up with Sean Forman, founder of the Sports-Reference network — which includes Baseball-Reference.com, Pro-Football-Reference.com, and Basketball-Reference.com — and talked about the genesis and future of his family of stats sites.
Bradley Woodrum: What inspired you to start the site back in 2000? I know David Appelman started FanGraphs to help his fantasy team. Did B-Ref have equally humble beginnings? Or was the expectation to become, essentially, the modern almanac for sports statistics?
Sean Forman: I had a similar creation story. There was really nobody doing an online encyclopedia and I thought it would be a great medium for that work. You could hyperlink between pages. So rather than leafing through a book (sounds crazy now) to hunt down Joe DiMaggio’s teammates you could just click a link and see them all. I didn’t expect it to do much. I worked hard on it for two months (while I was in grad school and should have been working on my dissertation) and got the basic site done.
BW: What was the online sports statistics scene back in 2000? What were your go-to resources for stats before Sports-Reference and before the Lahman database?
SF: The Lahman DB was the first bones of the site. It wouldn’t have happened without Lahman’s DB and the work of Pete Palmer that the Lahman DB is based upon. There was no historical content really online in 2000. TotalBaseball.com had a site, but it was barely usable. I was a disciple of Jakob Nielsen at that time, so my focus on usability and ease of use really paid off initially as there was so much cruft out there in web design. Splash pages, flash sites, image maps, blink and marquees.

BW: I understand you were previously a teacher before working on Sports-Reference full time. What was that transition like? And how did you finally make the decision to go full time?
SF: I was a full-time math/CS professor for six years. I actually completed the site before taking that job. During that time, I did B-R in my free time. One mitigating factor is that we weren’t updating in-season at that time, so the stress was a lot lower and we didn’t need to be as on top of things. I could leave it for a week and not worry about it.
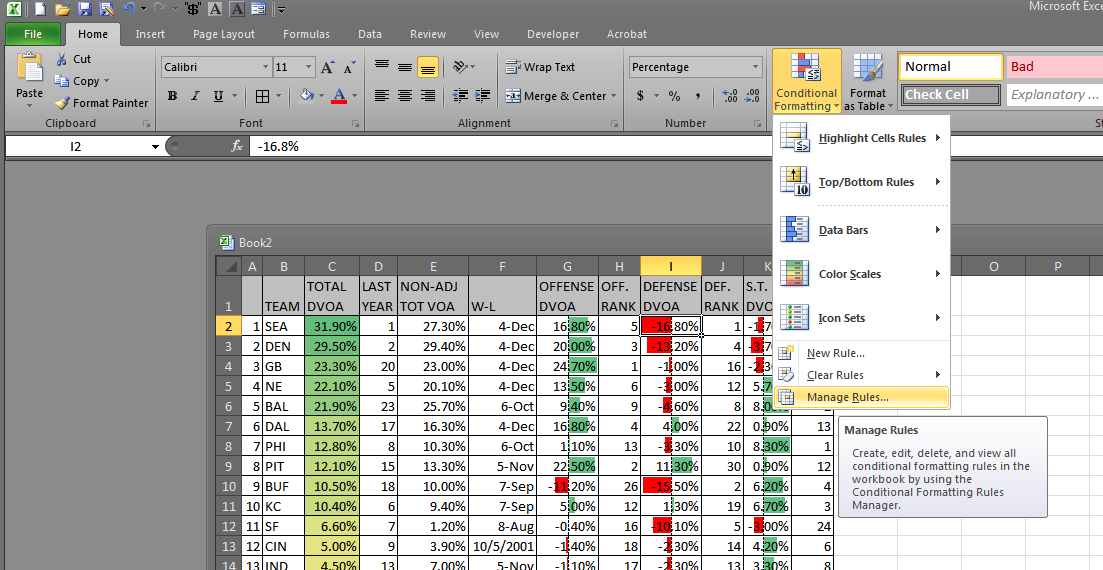
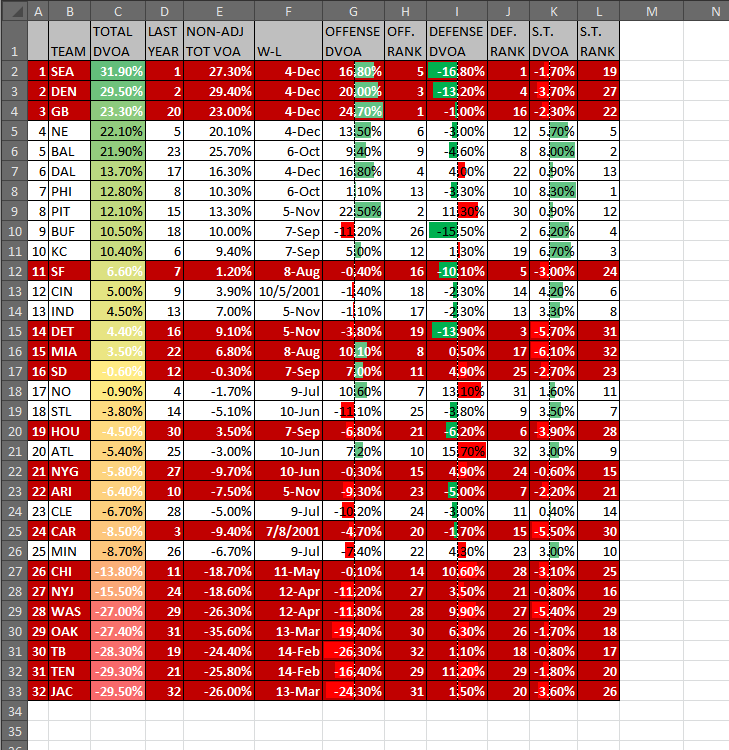
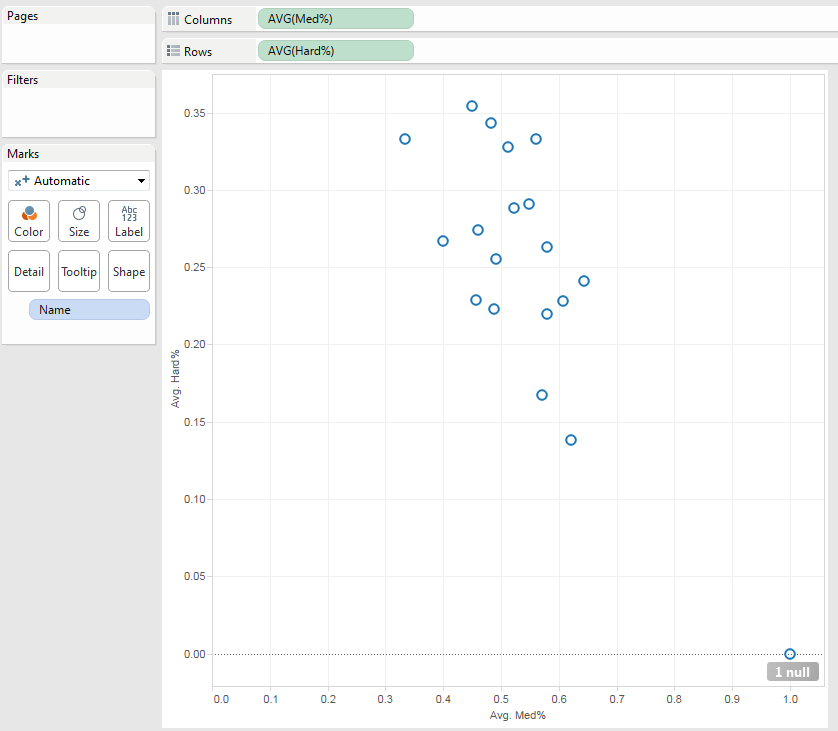
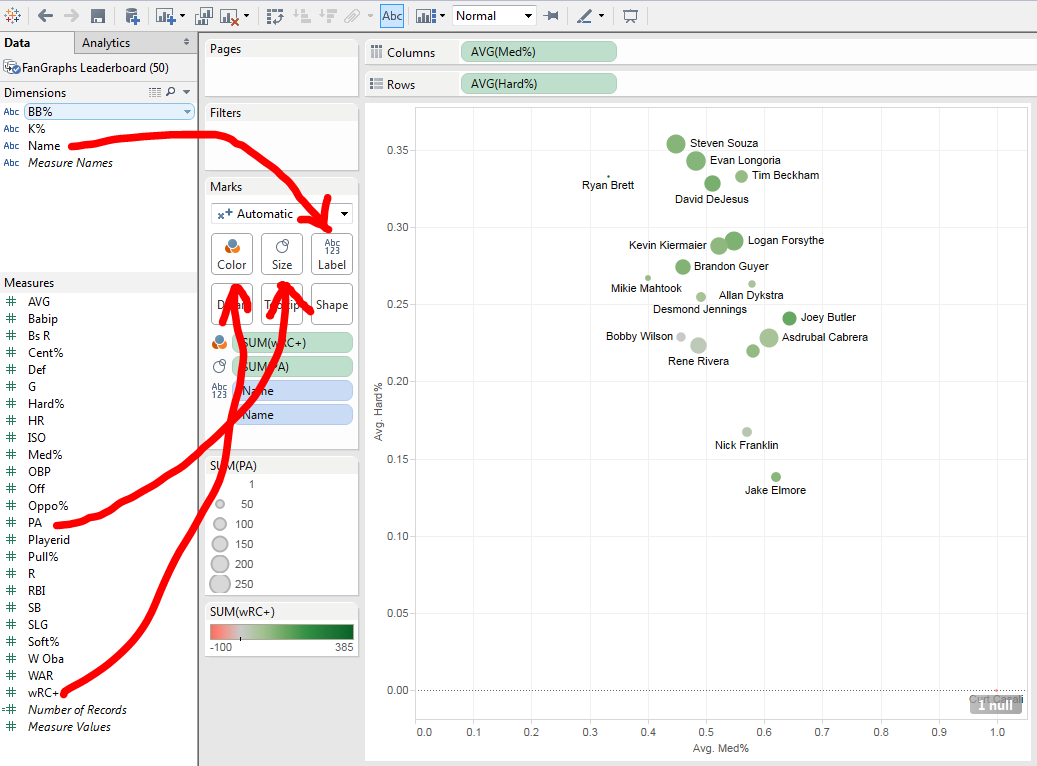
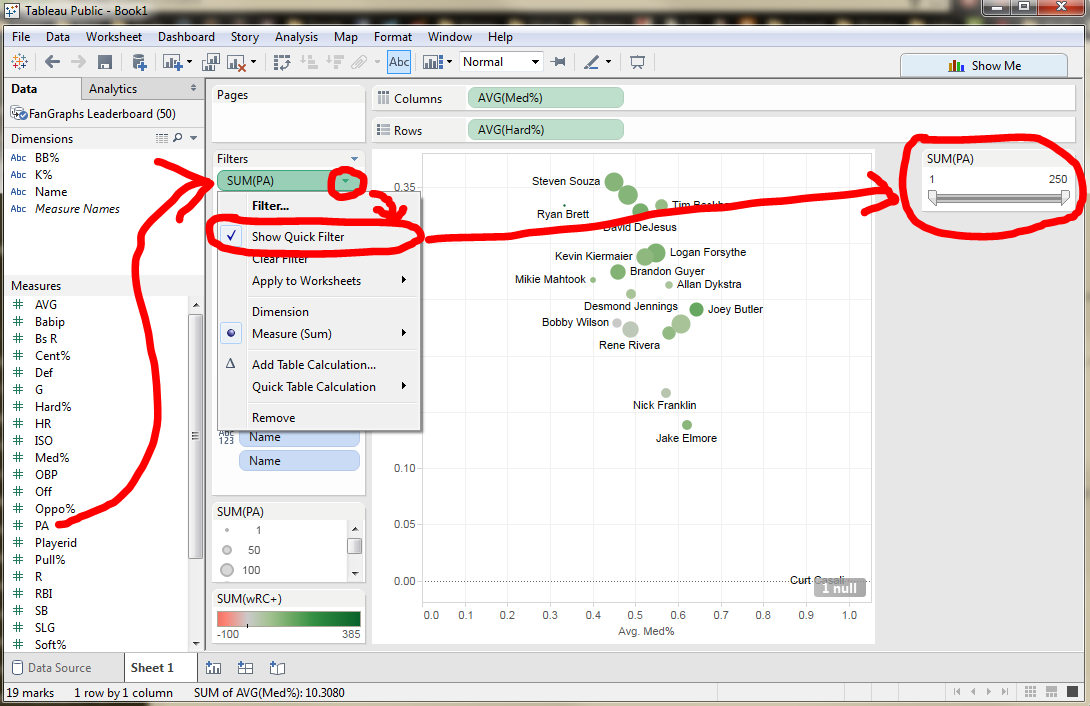
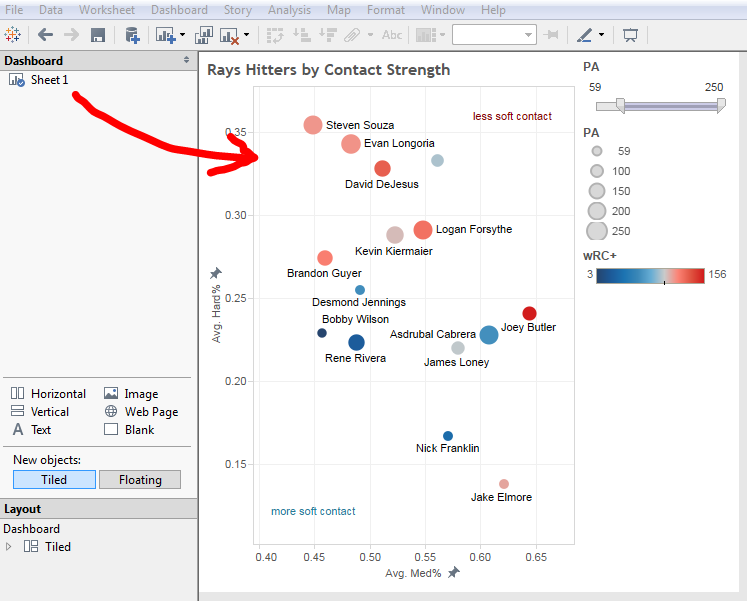
BW: The Sports-Ref family is famous for its Spartan design — outside of the player pictures on B-Ref, there’s, what, a single PNG on the whole site, and that’s the logo. Even the interactive charts and graphs have a minimalist design. Has this aesthetic lasted the test of time for its functionality, or is it more just the site’s personality at this point?
SF: [It has a] few more [pictures] than that, but not many. We are trying to reduce them further.
It’s both our personality and for functionality reasons. I’ve heard some people call it the Craigslist of baseball stats. I like to think one of our strengths is that we can view the site from the user perspective better than most. That is really hard to do. We have 250 MB internet connections and gigantic phones and use the latest chrome browser and know internally how the site is put together, but a new user has none of that. They may be on an old windows machine with a 1200×800 resolution with a slow internet connection. Basically you’ve got to make things more obvious than you can even imagine being necessary.
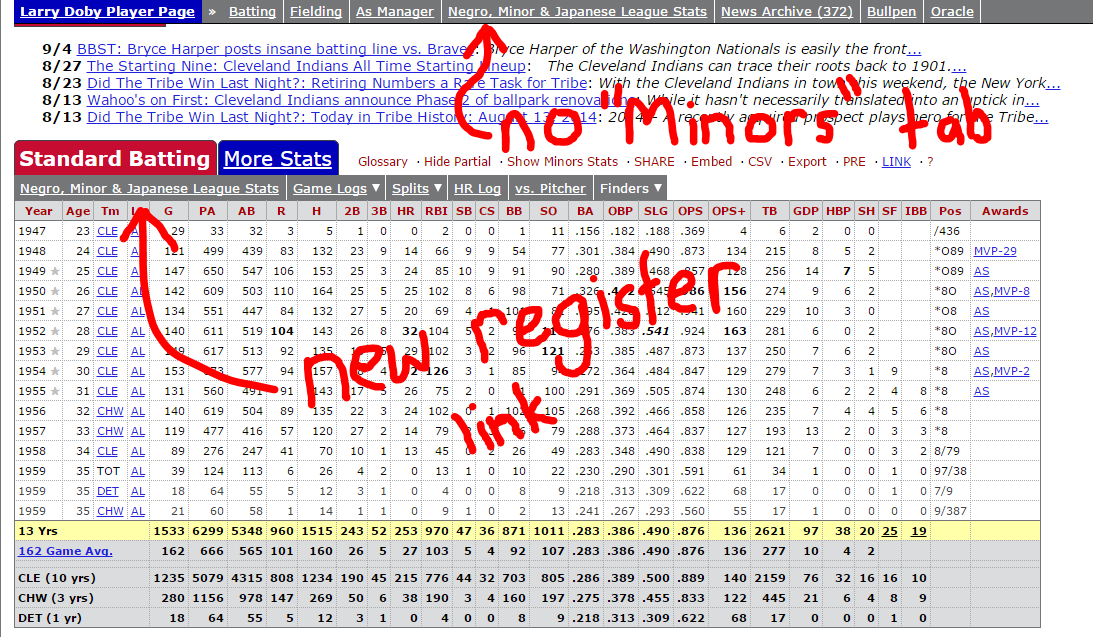
We had a good example of this last week. We launched a new “register” section to combine the minors, Japan, NLB, Cuba and KBO stats into one area. Larry Doby is our test case for this. We called it register because we’ve got 70+ Sporting News Baseball Registers on our shelves and those showed the stats pretty much in the way we are doing it now. Within 20 minutes of launching, we got complaints that we’d taken away the minor league stats, asking are were expecting people to “sign-up” (read register) for the site. We should have caught that on our end, but we were able to fix it quickly and improve the clarity in the process.
BW: Speaking of the lesser known stats, the B-Ref Bullpen has developed into a go-to resource for baseball fans and writers, oftentimes trumping player’s actual Wikipedia pages. What inspired you to add this feature? Do you expect the basketball and football sites will eventually get their own wiki’s too?
SF: I started it because 1) I love Wikipedia. Wikipedia may be the greatest human accomplishment of all time. I’m not joking. Think about how valuable having all of that knowledge in one place is. (DONATE!). 2) For good reason Wikipedia starts their baseball articles with info like “Ty Cobb is an American baseball player…” and I thought that it would be interesting to put together pages for players that were more in depth and baseball oriented than wiki would want. The funny thing is that the star players get almost no treatment on our site, but we have 1000’s of words on Japanese players, Negro Leaguers and early players. It makes sense as there is a need to know about those players.
As for the other sites, we probably should have just done it by now. I’ve been skeptical we’d get any traction with them, but it would have been a good idea to start them.
BW: Baseball, basketball, football, hockey, and Olympics. Is there any area remaining that you might want to add? Maybe prep / high school stats?
SF: The great frontier is soccer (fbref.com). It makes the history of professional baseball look like child’s play. We have a great dataset and hope to get something launched this winter. My favorite stat I’ve discovered is that the English Wikipedia has more pro soccer clubs listed than there have been players in Major League Baseball history.
BW: Oh wow. I can’t even conceptualize that many teams. I’m looking forward to see how you handle that!
A big thanks to Sean for taking the time to talk with us! Be sure to give him a follow on Twitter at @Sean_Forman.





















{kind=link}