How To Use R For Sports Stats, Part 2: Visualization and Analysis
Welcome back! In Part 1 of this series, we went over the bare bones of using R–loading data, pulling out different subsets, and doing basic statistical tests. This is all cool enough, but if you’re going to take the time to learn R, you’re probably looking for something… more out of your investment.
One of R’s greatest strengths as a programming language is how it’s both powerful and easy-to-use when it comes to data visualization and statistical analysis. Fortunately, both of these are things we’re fairly interested in. In this post, we’ll work through some of the basic ways of visualizing and analyzing data in R–and point you towards where you can learn more.
(Before we start, one commenter reminded me that it can be very helpful to use an IDE when coding. Integrated development environments, like RStudio, work similarly to the basic R console, but provide helpful features like code autocompletion, better-integrated documentation, etc. I’ll keep taking screenshots in the R console for consistency, but feel free to try out an IDE and see if it works for you.)
Look At That Data
We’ll be using the same set of 2013-14 batter data that we did last time, so download that (if you haven’t already) and load it back up in R:
fgdata = read.csv("FGdat.csv")
Possibly my favorite thing about R is how, often, all it takes is a very short function to create something pretty cool. Let’s say you want to make a histogram–a chart that plots the frequency counts of a given variable. You might think you have to run a bunch of different commands to name the type of chart, load your data into the chart, plot all the points, and so on? Nope:
hist(fgdata$wRC)
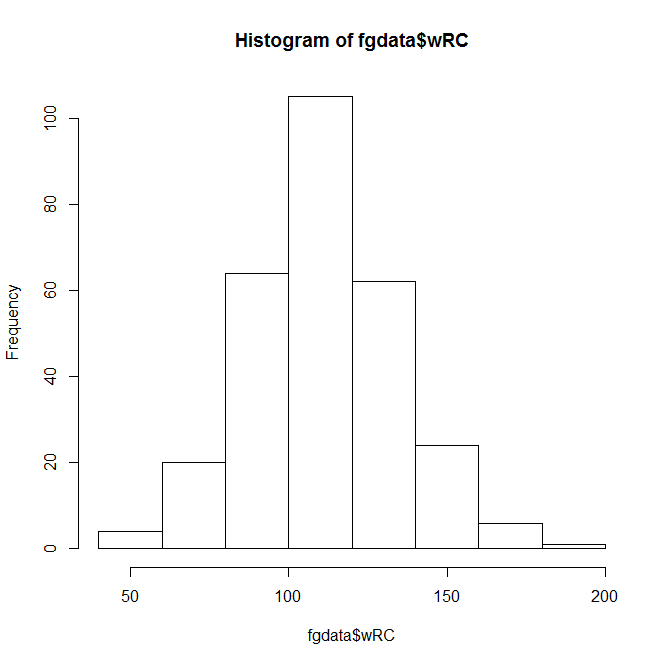 This Instant Histogram(™) displays how many players have a wRC+ in the range a given bar takes up in the x-axis. This histogram looks like a pretty normal, bell-curveish distribution, with an average a bit over 100–which makes sense, since the players with a below-average wRC+ won’t get enough playing time to qualify for our data set.
This Instant Histogram(™) displays how many players have a wRC+ in the range a given bar takes up in the x-axis. This histogram looks like a pretty normal, bell-curveish distribution, with an average a bit over 100–which makes sense, since the players with a below-average wRC+ won’t get enough playing time to qualify for our data set.
(You can confirm this quantitatively by using a function like summary(fgdata$wRC).)
The hist() function, right out of the box, displays the data and does it quickly–but it doesn’t look that great. You can spend endless amounts of time customizing charts in R, but let’s add a few parameters to make this look nicer.
hist(fgdata$wRC, breaks=25, main="Distribution of wRC+, 2013 - 2014", xlab="wRC+", ylab= NULL, col="darkorange2")
In this command, ‘breaks’ is the number of bars in the chart, ‘main’ is the chart title, ‘xlab’ and ‘ylab’ are the axis titles, and ‘col’ is the color. R recognizes a pretty wide range of colors, though you can use RGB, hex, etc. if you’re more familiar with them.
Anyway, here’s the result:
 A bit better, right? The distribution doesn’t look quite as normal now, but it’s still pretty close–we can actually add a bell curve to eyeball far off it is.
A bit better, right? The distribution doesn’t look quite as normal now, but it’s still pretty close–we can actually add a bell curve to eyeball far off it is.
hist(fgdata$wRC, breaks=25, freq = FALSE, main="Distribution of wRC+, 2013 - 2014", xlab="wRC+", ylab= NULL, col="darkorange2") curve(dnorm(x, mean=mean(fgdata$wRC), sd=sd(fgdata$wRC)), add=TRUE, col="darkblue", lwd=2)
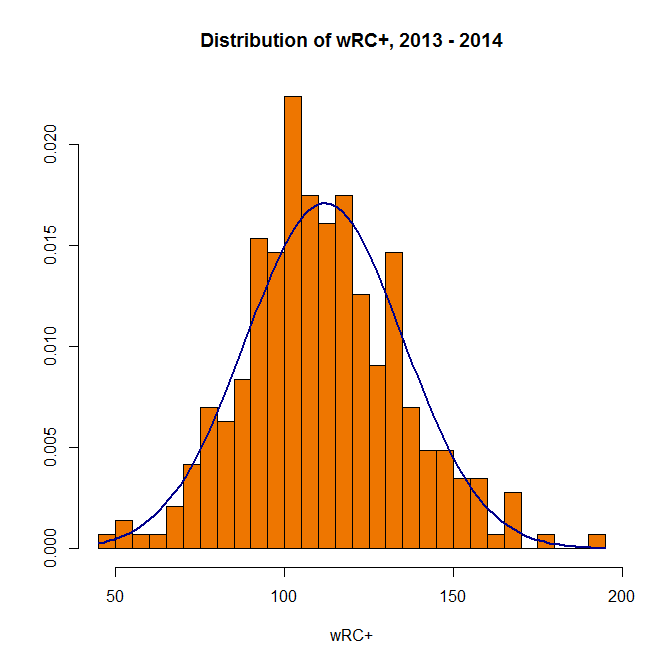
(In the first line above, “freq = FALSE” indicates that the y-axis will be a probability density rather than a frequency count; the second line creates a normal curve with the same mean and standard deviation as your data set. Also, it’s blue.)
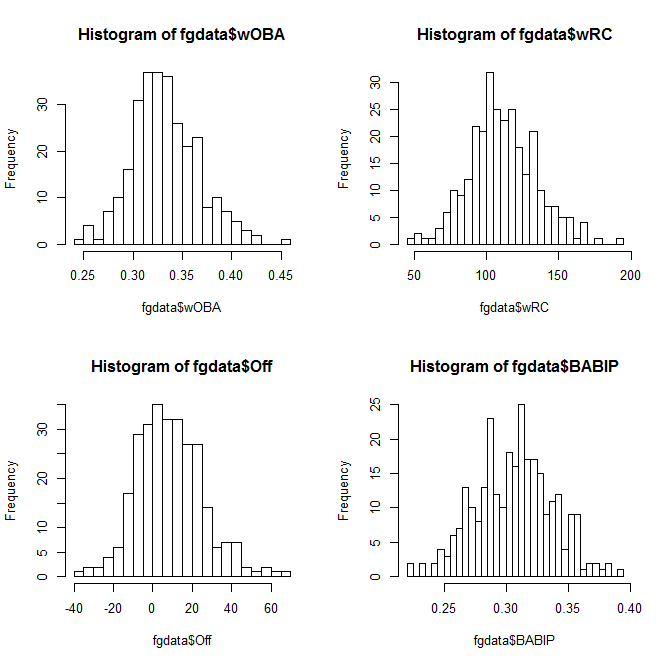
You can also plot multiple charts at the same time–use the par(mfrow) function with the preferred number of rows and columns:
par(mfrow=c(2,2)) hist(fgdata$wOBA, breaks=25) hist(fgdata$wRC, breaks=25) hist(fgdata$Off, breaks=25) hist(fgdata$BABIP, breaks=25)
 When you want to save your plots, you can copy them to your clipboard–or create and save an image file directly from R:
When you want to save your plots, you can copy them to your clipboard–or create and save an image file directly from R:
png(file="whatisitgoodfor.png",width=400,height=350) hist(fgdata$WAR, breaks=25) dev.off()
(It’ll show up in the same directory you’re loading your data set from.)
So that covers histograms. You can create bar charts, pie charts, and all of that, but you’re probably more interested in everyone’s favorite, the scatterplot.
At its most basic, the plot function is literally plot() with the two variables you want to compare:
plot(fgdata$SLG, fgdata$ISO)
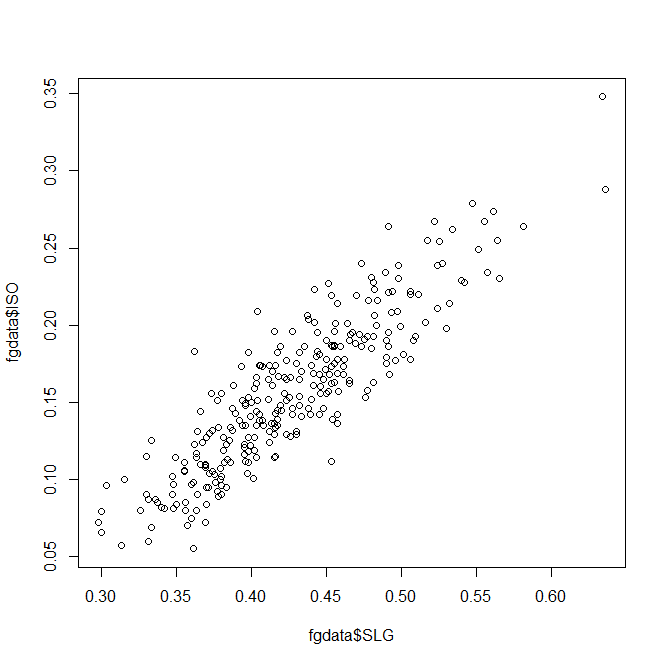 Unsurprisingly, slugging percentage and ISO are fairly well-correlated. Results-wise, we’re starting to push against the limits of our data set–too many of these stats are directly connected to find anything interesting.
Unsurprisingly, slugging percentage and ISO are fairly well-correlated. Results-wise, we’re starting to push against the limits of our data set–too many of these stats are directly connected to find anything interesting.
So let’s take a different tack and look at year-over-year trends. There are several ways you could do this in R, but we’ll use a fairly straightforward one. Subset your data into 2013 and 2014 sets,
fg13 = subset(fgdata, Season == "2013") fg14 = subset(fgdata, Season == "2014")
then merge() the two by name. This will create one large dataset with two sets of columns: one with a player’s 2013 stats and one with their 2014 stats. (Players who only appeared in one season will be omitted automatically.)
yby= merge(fg13, fg14, by=("Name"))
head(yby)
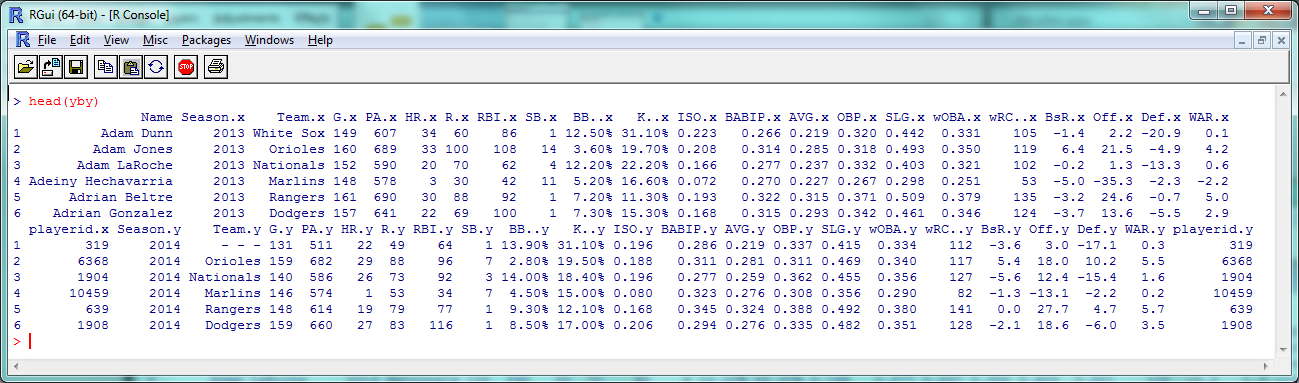 As you can see, 2013 stats have an .x after them and 2014 stats have a .y. So instead of comparing ISO to SLG, let’s see how ISO holds up year-to-year:
As you can see, 2013 stats have an .x after them and 2014 stats have a .y. So instead of comparing ISO to SLG, let’s see how ISO holds up year-to-year:
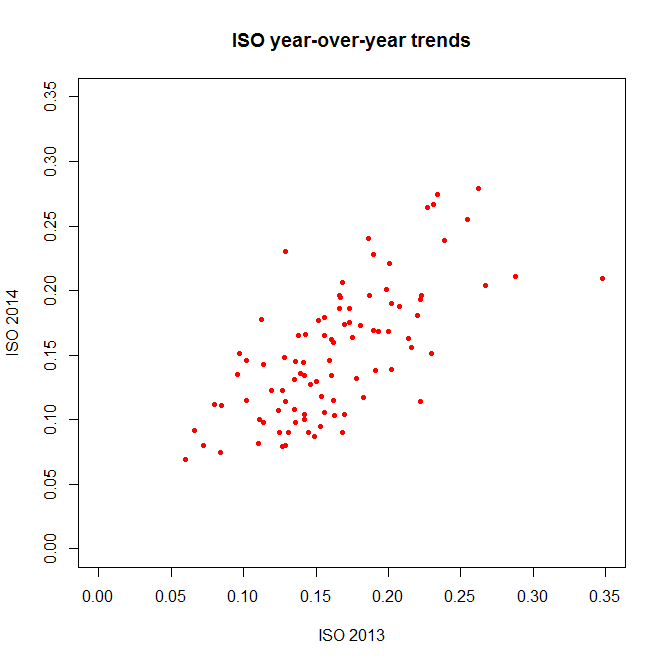
plot(yby$ISO.x, yby$ISO.y, pch=20, col="red", main="ISO year-over-year trends", xlab="ISO 2013", ylab="ISO 2014")
 (The ‘pch’ argument sets the shape of the data points; ‘xlim’ and ‘ylim’ set the extremes of each axis.)
(The ‘pch’ argument sets the shape of the data points; ‘xlim’ and ‘ylim’ set the extremes of each axis.)
Again, a decent correlation–but just *how* decent? Let’s turn to the numbers.
Relations and Correlations
If you’re a frequent FanGraphs reader, you’re probably familiar with at least one statistical metric: r², the square of the correlation coefficient. An r² near 1 indicates that two variables are highly-correlated; an r² near 0 indicates they aren’t.
As a refresher without getting too deep into the stats: when you’re ‘finding the r²’ of a plot like the one above, what you’re usually doing is saying there’s a linear relationship between the two variables, that could be described in a y = mx + b equation with an intercept and slope; the r² is then basically measuring how accurately the data fits that equation.
So to find the r² that we all know and love, you want R to create a linear model between the two variables you’re interested in. You can access this by getting a summary of the lm() function:
summary(lm(yby$ISO.x ~ yby$ISO.y))
 The coefficients, p-values, etc., are interesting and would be worth examining in a more theory-focused post, but you’re looking for the “Multiple R-squared” value near the bottom–turns out to be .4715 here, which is fairly good if not incredible. How does this compare to other stats?
The coefficients, p-values, etc., are interesting and would be worth examining in a more theory-focused post, but you’re looking for the “Multiple R-squared” value near the bottom–turns out to be .4715 here, which is fairly good if not incredible. How does this compare to other stats?
summary(lm(yby$BsR.x ~ yby$BsR.y)) > Multiple R-squared: 0.4306 summary(lm(yby$WAR.x ~ yby$WAR.y)) > Multiple R-squared: 0.1568 summary(lm(yby$BABIP.x ~ yby$BABIP.y)) > Multiple R-squared: 0.2302
BsR is about as consistent as ISO, but WAR has a smaller year-to-year correlation than you might expect. BABIP, less surprisingly, is even less correlated.
Let’s do one more basic statistical test: the t-test, which is often used to see if two sets of numeric data are significantly different from one another. This isn’t as commonly seen in sports analysis (because it doesn’t often tell us much for the data we most often work with), but just to run through how it works in R, let’s compare the ISO of low-K versus high-K hitters. First, we need to convert the percentages in the K% column to actual numbers:
fgdata$K. = as.numeric(sub("%","",fgdata$K.))/100
then subset out the low-K% and high-K% hitters:
lowk = subset(fgdata, K. < .15) highk = subset(fgdata, K. > .2)
Then, finally, run the t-test:
t.test(lowk$ISO, highk$ISO)
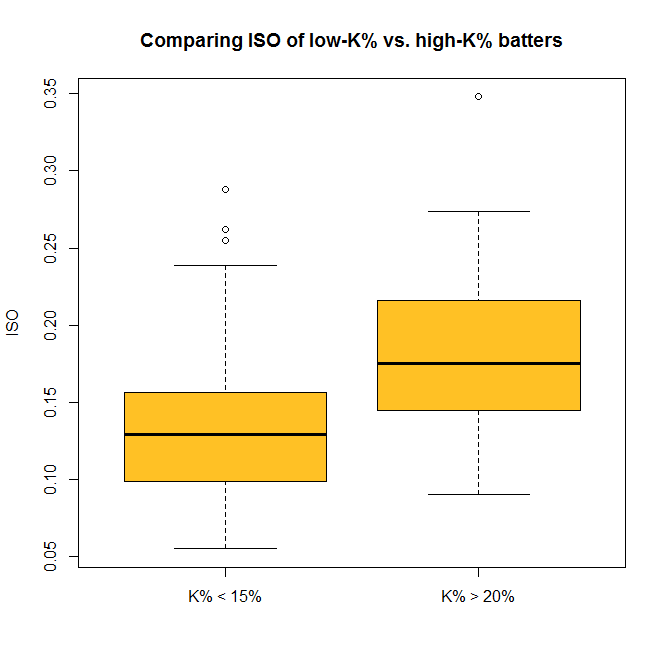
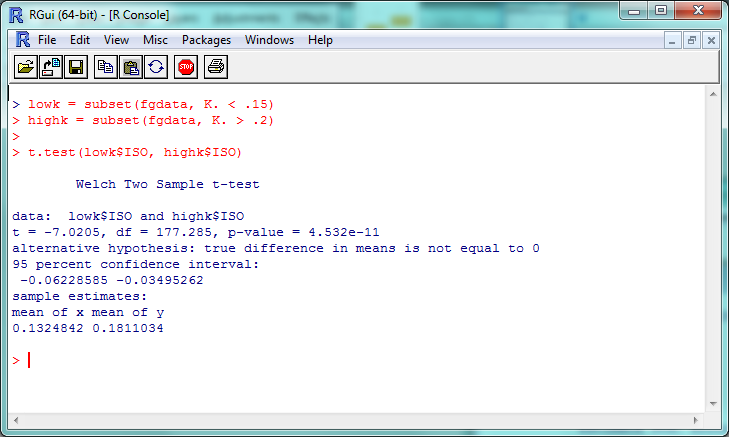 The “p-value” here is about 4.5 x 10^-11 (or 0.000000000045); a p-value less than .05 is generally considered significant, so we can consider this evidence that the ISO of high-K% hitters is significantly different than that of low-K% hitters. We can check this out visually with a boxplot–and you thought we were done with visualization, didn’t you?
The “p-value” here is about 4.5 x 10^-11 (or 0.000000000045); a p-value less than .05 is generally considered significant, so we can consider this evidence that the ISO of high-K% hitters is significantly different than that of low-K% hitters. We can check this out visually with a boxplot–and you thought we were done with visualization, didn’t you?
boxplot(lowk$ISO, highk$ISO, names=c("K% < 15%","K% > 20%"), ylab="ISO", main="Comparing ISO of low-K% vs. high-K% batters", col="goldenrod1")
 So now you can do some standard statistical tests in R–but be careful. It’s incredibly tempting to just start testing every variable you can get your hands on, but doing so makes it much more likely that you’ll run into a false positive or a random correlation. So if you’re testing something, try to have a good reason for it.
So now you can do some standard statistical tests in R–but be careful. It’s incredibly tempting to just start testing every variable you can get your hands on, but doing so makes it much more likely that you’ll run into a false positive or a random correlation. So if you’re testing something, try to have a good reason for it.
…And Beyond
We’ve covered a fair amount, but again, this only begins to cover the potential R provides for visual and statistical analysis. For one example of what’s possible in both these areas, check out this analysis of an online trivia league that was done entirely within R.
If you want to replicate his findings, though (which you can, since he’s posted the code and data online!), you’ll need to install packages, extensions for R that give you even more functionality. The ggplot2 package, for example, is incredibly popular for people who want to create especially cool-looking charts. You can install it with the command
install.packages("ggplot2")
and visit http://ggplot2.org/ to learn more. If R doesn’t do something you want it to out of the box, odds are there’s a package out there that will help you.
That’s probably enough for this week; here’s the script with all of this week’s code. In our next (last?) part of this series, we’ll look at taking one more step: using R to create (very) basic projections.
Brice lives in the Washington, DC area, where he does communications for linguistics and space exploration organizations. Brice has previously written for Ars Technica, Discovery News and the Winston-Salem Journal. He's on Twitter at @KilroyWasHere.
This series is soooo good! TechGraphs in its ideal form!
Thanks for the posts! Very helpful and enlightening
No RStudio?
It’s in there! See paragraph 3.
Another great tutorial. But I can’t get any of the histograms/plots/graphs. When I type in the command, and hit return, nothing happens. That must be some limitation of my system? All the tabular results come out fine.
You should have a window pop up with the chart in it–it will probably be named something like “R Graphics: Device 1”. If it doesn’t show up immediately, try going to the Windows menu within R (presuming you’re on a PC) and seeing if it’s listed there.
The commands that let you save graphs to a file outside of R should work regardless, though I’d hate for that to be the only way you can see them.
Hey, nice post!! I did want to point out that you did your linear model backwards for the year-by-year correlations.
When you write lm(yby$ISO.x ~ yby$ISO.y), you are indicating that yby$ISO.x (the 2013 data) is the dependent variable and yby$ISO.y (the 2014 data) is the independent variable. So you are really checking to see if the 2014 numbers tell you something about the 2013 numbers. It should be the other way around!
It doesn’t make too much difference in the long run, as you will get pretty similar results, but it often does make a difference in general.. especially when it comes to interpreting results.
Thanks! You’re totally right–I was a bit lax in this case because all we care about here is the r^2, which (I believe) will be the same either way . I’ll be coming back to linear models in the next post, though, where we’ll be *slightly* more rigorous.
Loving the series so far, Brice. There is one thing that has been annoying the heck out of me… I’m trying to get the curve to work, and it does when I copy and paste your code. However, when I type it out myself (copying yours exactly) I get the same error about an unexpected symbol. Can you offer any insight into why this is?