If you’ve spent a sufficient amount of time messing around with sports statistics, there’s a good chance the following two things have happened, in order:
- You probably started off with Excel, because Excel does a lot of stuff pretty easily and everyone has Microsoft Office.
- At some point, you mentioned to someone that you use Excel to do statistical analysis and got a response along the lines of, “Oh, that’s cool, but you should really be using R.”
Politeness issues aside, they might well be right.
R is a programming language and software platform commonly used, particularly in research and academia, for data analysis and visualization. Because it’s a programming language, the learning curve is a bit steeper than it is for something like Excel–but if you dig into it, you’ll find that R makes it possible to do a wider variety of tasks more quickly. If you’re interested in finding interesting insights with just a few lines of code, if you want to easily work with large sets of data, or if you’re interested in using most any statistical test known to man, you should take a look at R.
Also, R is totally free, both as in “open-source” and as in “costs no money”. So that’s nice.
In this series, we’ll learn the basics of working in R with the goal of exploring sports data—baseball, in particular. I’m going to presume that you have no background whatsoever in coding or programming, but to keep things moving, I’ll try not to get too bogged down in the details (like how “=” does something different from “==”) unless absolutely necessary. This guide was made using R on Windows 7, but most everything should be the same on whatever OS you use.
Okay, let’s do this.
Getting Started
You can download R from https://cran.rstudio.com/.
You’ll have to click on a few links (you want the ‘base’ install) and actually install R, but once that’s done you should have a screen that looks like:
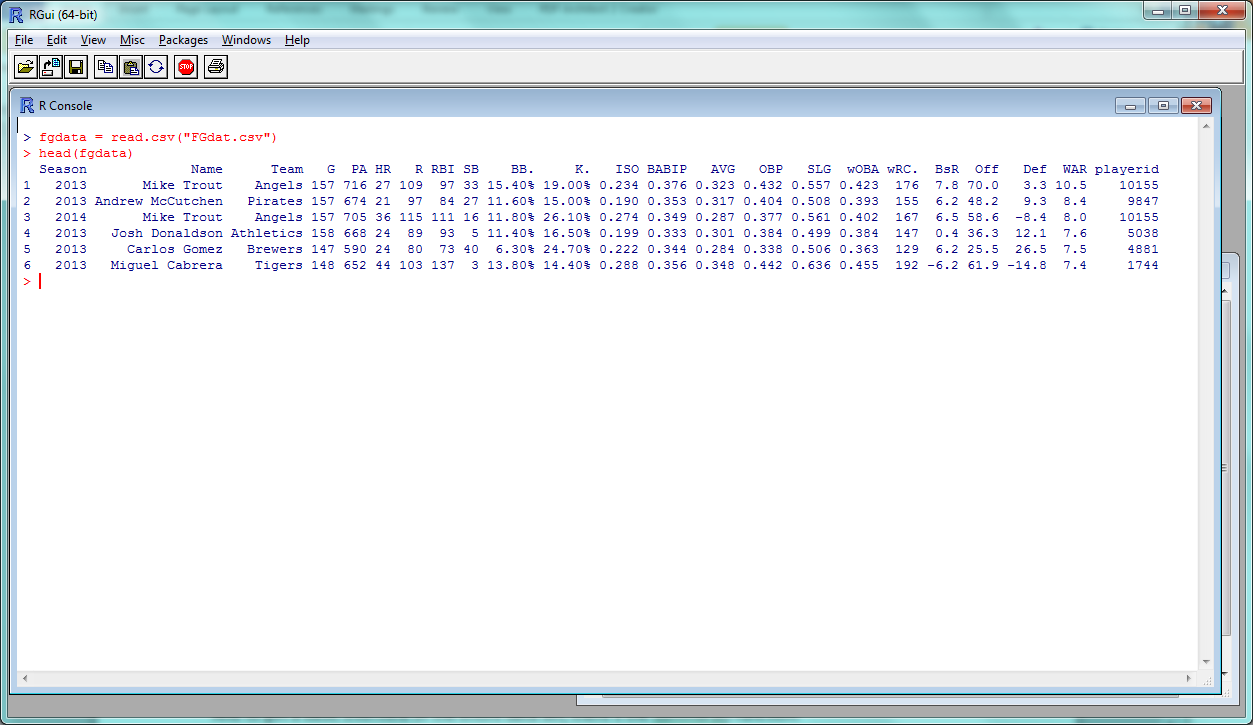
 The “R console” is where your code is soon going to run–but first, we need some data. Let’s take FanGraphs’ standard dashboard data for qualifying MLB batters in 2013 and 2014. Save it as something short, like “FGdat.csv”. (If you have a custom FG dashboard or just want to take a shortcut, you can just download the data we’ll be using here.)
The “R console” is where your code is soon going to run–but first, we need some data. Let’s take FanGraphs’ standard dashboard data for qualifying MLB batters in 2013 and 2014. Save it as something short, like “FGdat.csv”. (If you have a custom FG dashboard or just want to take a shortcut, you can just download the data we’ll be using here.)
In R, we’ll be focusing mostly on functions (that look like, say, function(arg1, arg2)), which are what actually do things, and naming the output of these functions so we can refer back to it later. For example, a line of R code might look like this:
fgdata = read.csv("FGdat.csv")
The function here is the read.csv(), which basically means “read this CSV file into R”, and the argument inside is the file that we want to read. The left part (fgdata =) is us saying that we want to take the data we’re reading and name it “fgdata”.
This is, in fact, the first line we want to run in R to load our data, so type/paste it in and hit Enter to execute it.
(You may get an error like cannot open file ‘FGdat.csv’: No such file or directory; if you do, you likely need to change the directory that R is trying to read files from. Go to “File” -> “Change dir”, and change the working directory to the folder you saved the CSV in, or just move the CSV to the folder R has listed as the working directory.)
If you didn’t get an error and R simply moves on to the next line, you should be good to go!
Basic Stats
The head() function returns the first 6 rows of data; since our data set is named “fgdata”, we can try this out with the line of code:
> head(fgdata)
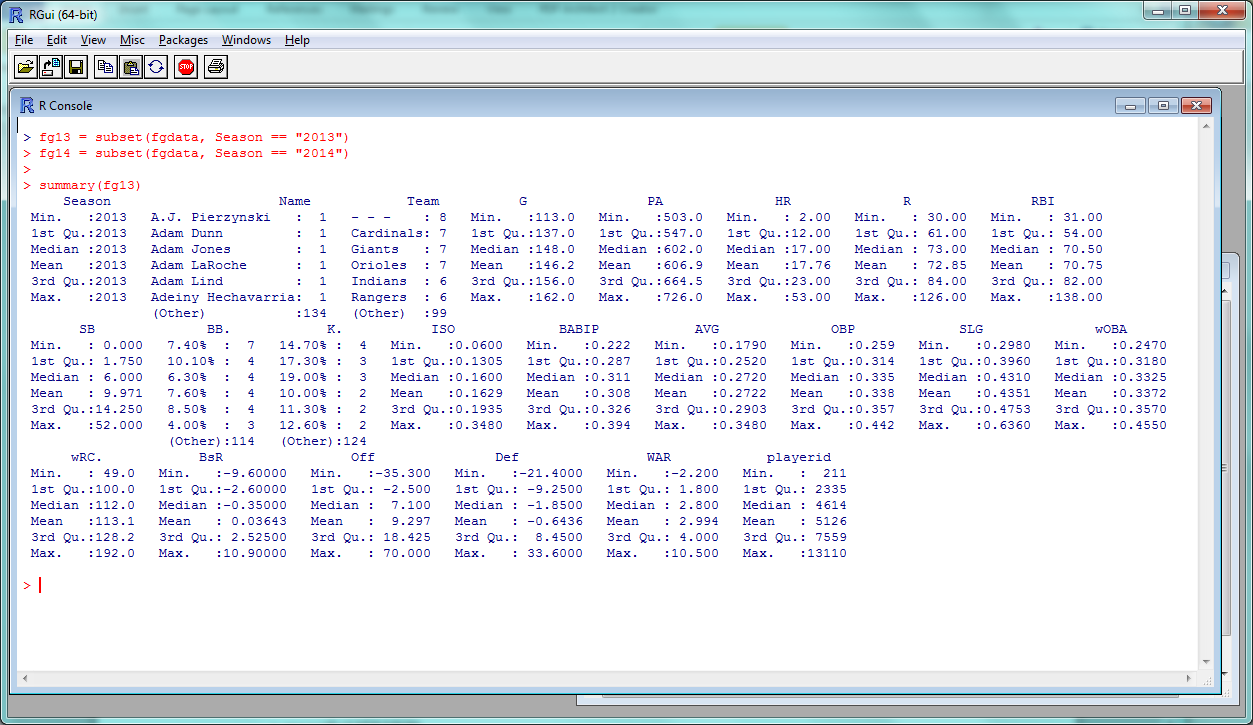
 And to get a basic overview of the entire data set, there’s the summary() function:
And to get a basic overview of the entire data set, there’s the summary() function:
> summary(fgdata)
 See! Already, data on 20 variables in the blink of an eye.
See! Already, data on 20 variables in the blink of an eye.
“1st Qu.” and “3rd Qu.” are the first and third quartiles; the mean, median, minimum and maximum should be self-explanatory. So we can see that the average player in this data set had roughly a .270 average with 17 dingers and 10 steals in 146 games–not far from Alex Gordon’s 2014, basically.
Want to compare how the 2013 and 2014 stats stack up? R makes it pretty easy to pick out subsets of data. It’s called, reasonably, the “subset” function, and all you need to include is the data set you’re taking a subset of and the criteria the subset data should conform to.
Since we have “Season” as a field in the table, we just need to say “Season == “2013”” to get the 2013 players and “Season == “2014”” to get the 2014 players. We’ll name these new data sets ‘fg13’ and ‘fg14’:
> fg13 = subset(fgdata, Season == "2013")
> fg14 = subset(fgdata, Season == "2014")
A quick check should confirm that, yes, the data did subset correctly:
> summary(fg13)
 and now we can do some basic statistical comparisons, like comparing the mean BABIPs between 2013 and 2014. (To single out a specific column in a data set, use the $ symbol.)
and now we can do some basic statistical comparisons, like comparing the mean BABIPs between 2013 and 2014. (To single out a specific column in a data set, use the $ symbol.)
> mean(fg13$BABIP)
> mean(fg14$BABIP)
You can do whatever basic statistical tests you like–sd() for the standard deviation, et cetera–and pull out different subsets of the data based on whatever criteria you like. So “HR > 20” for all players who hit more than 20 home runs, or “Player == “Mike Trout”” to get data for all players named Mike Trout:
> fgtrout = subset(fgdata, Name == "Mike Trout")
> fgtrout
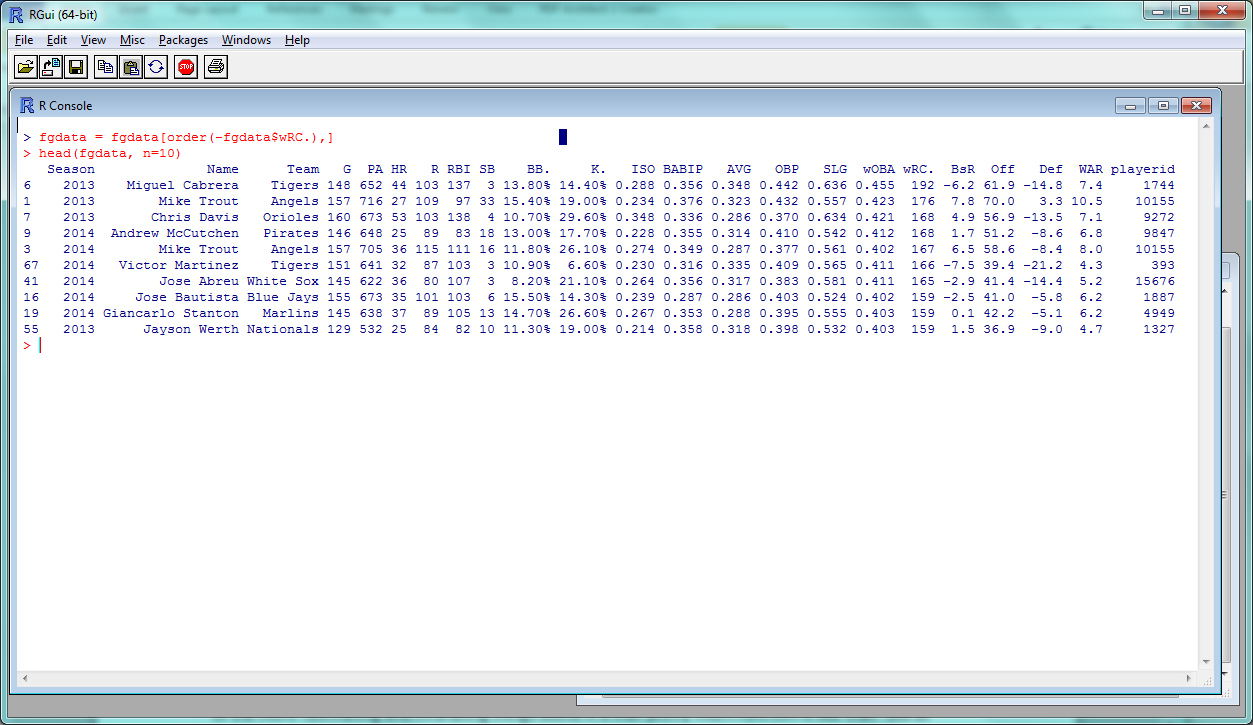
 Lastly, it’s not too common to need to reorder your data in R, but if you do, you can do so with the order() function. This line sorts the data by wRC+, ascending order:
Lastly, it’s not too common to need to reorder your data in R, but if you do, you can do so with the order() function. This line sorts the data by wRC+, ascending order:
> fgdata = fgdata[order(fgdata$wRC.),]
then returns the top 10 rows:
> head(fgdata, n = 10)
You can sort in descending order by placing a minus sign before the column:
> fgdata = fgdata[order(-fgdata$wRC.),]
 And, as you’ve probably noticed, most of these functions can be tweaked or expanded depending on the different arguments you use–adding “n = 10” to head(), for example, to view 10 rows instead of 6. One of the more fascinating and infuriating things about R is that pretty much every function is like that–but at least they’re all documented!
And, as you’ve probably noticed, most of these functions can be tweaked or expanded depending on the different arguments you use–adding “n = 10” to head(), for example, to view 10 rows instead of 6. One of the more fascinating and infuriating things about R is that pretty much every function is like that–but at least they’re all documented!
And, of course, you can access the documentation through a function. Use help() (help(head), help(summary), etc.) and a page will pop up with the arguments, and more additional details than you probably ever wanted.
Wrap-up
One final note: typing code directly into the console is fine, but it gets a bit annoying if you want to write more than a line or two. Instead, you can create a new window within R to load, edit and run scripts. In Windows, use “Ctrl+N” to open a new script window. Type some code; to run it, highlight the lines you want to run and hit “Ctrl+R”.
You can also use these windows to save your R script in R files–as I’ve done here for all the code used in this article. Feel free to download and start tinkering.
So those are the basics of R; not enough to really show its potential, but enough to start experimenting and exploring as you wish. For Part 2, we’ll start some data plotting and correlation tests, and in Part 3 we’ll try to recreate some basic baseball projection models. I actually haven’t done this before in R, so it should be interesting. Stay tuned!
(Thanks to Jim Hohmann for helping test this article.)